 Evolution
Evolution
On Protein Evolution, PZ Myers Is Way Off the Mark
PZ Myers’s latest salvos on protein evolution (here and here) are way off the mark. Of course his attacks are written in his usual insulting style. That’s not interesting. What is interesting is how he misrepresents our work, uses faulty logic, and fails to engage our arguments. I know that anything I write here is unlikely to persuade him. So this isn’t written for PZ. But there may be other readers with open minds who are paying attention.
PZ begins by expounding on the supposed failings of the peer-reviewed paper in BIO-Complexity that Doug Axe and I published earlier this year. The paper examines how hard it is to convert the function of one extant enzyme to that of a closely related (paralogous) enzyme. A couple of things to note:
- We explained in the paper why ancestral forms were not used, and why we weren’t trying to reconstruct evolutionary history, and
- the two enzymes in question have no overlapping activity between them, even though they are very similar structurally.
What he says is not a new critique, but I will quote some to give you the flavor. Regarding our choice of extant proteins, PZ says:
The cousin problem. You should have picked up on the key problem from my short description above: they picked two extant proteins and then asked how they could have evolved from each other. Imagine if I picked one of my many cousins — say, the tall, red-headed Mormon fellow from Oregon, or the slender fan of horses in California — and started enumerating our many differences and declared that I couldn’t possibly have evolved from either of them. You would rightly stop me and suggest that maybe my problem is that I didn’t evolve from my cousins — that maybe the smarter approach would be to look at our respective parents, and the grandparents we have in common, and trace the lines of descent.
To which I reply:
OK, let’s go with the whimsical analogy. If you look at the DNA sequences of PZ and his cousins, you certainly could deduce that they are related. Further, if all you want to do is make PZ redheaded, you might be able to figure out what chunks of DNA need to be swapped to make it happen, without retracing lines of descent or evolving anything. Then, once you know how many changes are necessary to make him a redhead, you have a good estimate of the minimum number changes it would take for an evolutionary process to make his clones into redheads (since he would have to reproduce asexually to actually mimic the kind of evolution our paper addresses).
In our paper we explicitly said we were not trying to retrace evolutionary history, or show how the two enzymes might have evolved from one another. We just wanted to turn one of them into a redhead, so to speak. And since they are supposedly evolutionary “cousins,” Darwinian theory claims that their genetic distance shouldn’t lie beyond the reach of blind and unguided evolutionary mechanisms.
PZ then moves on to attacking a post I wrote recently. The whole point of my post, which PZ seems to have missed, was that ancestral reconstruction solves nothing for neo-Darwinism. The post began as a response to recent work from Carroll, Ortlund, and Thornton. I actually did read the paper, and think it’s a fine piece of research. No question. I also think it substantiates the difficulty of recruiting proteins to new functions, no matter where you start.
Carroll et al. have been studying two types of corticosteroid hormone receptors for years. Both types of receptors have overlapping activity. Using phylogenetic analysis, Carroll et al. reconstituted the putative ancestral receptor from which the extant kinds of receptor came. They found that to achieve conversion of that ancestral form (which resembles the mineralocorticoid receptor in function) to a new glucocorticoid receptor, it would have taken a gene duplication plus three mutations, in a particular order. That’s a lot of change for an undirected process to accomplish, without being sidetracked by inactivation or gene loss first.
In my post I go into more detail about why this is highly unlikely. I also describe how many changes we estimate it would take to convert an enzyme to a completely new function, based on our own study. That kind of conversion requires a minimum of seven or more mutations. No new function until all seven are in place.
If our estimate is correct, that poses a serious challenge, in fact an impossible challenge, to neo-Darwinism. The waiting time for seven specific neutral or slightly deleterious mutations to occur in a bacterial population is on the order of 10^27 years.1
When PZ finally does quote from my post concerning the above-mentioned waiting time, he mocks the whole problem by comparing it to bridge, and says:
If I played bridge very, very fast, dealing out one hand every minute, that means I’d still have to wait 1.1 million years to get any particular hand you might specify ahead of time…and my life expectancy is only on the order of 102 years. Therefore, bridge is impossible. Similarly, if you add up all the nucleotide differences between me and my cousin, the likelihoods of these particular individuals is infinitesimally small…but so what? We’re here. [emphasis added]
I respond: Ah, but if you need your cousin to have a specific genotype to permit a bone marrow transplant, only a few HLA haplotypes will do. If you need all the cards in your bridge hand to be of a certain suit, only a few hands will do. Yes, you might have to wait a long time.
And if you need to make an enzyme capable of producing 8-amino-7-oxononanoate, so as to produce biotin, not just any protein sequence will do. Plus you’ll need a whole lot more than that one protein.
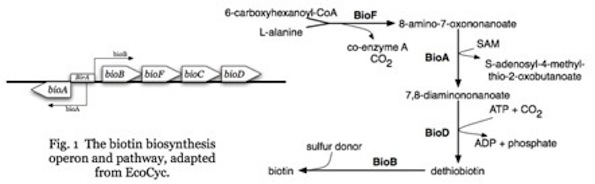
The problem is one of sequence specificity, or put another way, specified complexity. Not just any sequence will do. Getting the right sequence may be easy or hard, depending on where you start and where you have to go. For enzymes, as we have seen, it can be very hard indeed.
PZ’s statement above, “…but so what? We’re here,” reveals his bias. In his mind, the fact that we are here trumps any level of improbability. We are here, therefore we must be the product of purely neo-Darwinian processes. That’s neither good science nor good logic. It’s called assuming the consequent. But if it’s the only explanation he will permit, it’s all he’s got.
The question that needs asking, though, is why we are here. How do we account for the vast diversity of particular proteins with particular functions, if functional conversion between proteins is difficult (or impossible)? Conversions that require two or three mutations (including any duplication) are probably possible. More than that and we need to invoke extraordinary luck, or intelligent guidance.
The question remains open, if you are open to all answers. Many more experiments need to be done to determine if most enzyme conversions are beyond the reach of neo-Darwinism. But that’s why we do experiments. And yes, it is science, even if the conclusions point in a direction PZ doesn’t want to go.
Notes:
(1) Thanks to the alert readers of PZ’s blog for pointing out that I erred when writing out the exponent. I wrote it out so as to avoid confusion about what 10^27 meant — I was writing for a general readership and I have seen too many exponents go haywire on the Internet. It should have read as a “1 with 27 zeros after it.” Doesn’t change the scope of the problem, but there it is.