 Education
Education
 Intelligent Design
Intelligent Design
 News Media
News Media
Responding to the Youtube Challenge to Discovery Institute: Does Any Critic Out There Understand Intelligent Design? Anyone? …Anyone?
Any critic making the inaccurate claim that Stephen C. Meyer is the “President of the Discovery Institute” is bound to be fairly uninformed about both intelligent design (ID) and the Discovery Institute.1 Thus, when I recently viewed a YouTube video making this very mistake while allegedly “Challenging the Discovery Institute to Discover,” I first thought: Why should I accept a challenge from someone who can’t even correctly “discover” the identity of our organization’s president?
Regardless, this video was enlightening, but not in the way that its creators intended. Rather than posing any difficult challenge for ID, the video unwittingly exposes the unfortunate ignorance that apparently abounds regarding the nature of the theory of intelligent design and how we detect and test for design in nature. In this regard, I view this response to the video as an opportunity–hopefully a teachable moment for the 40,000+ people who have apparently viewed the video and the handful who have e-mailed us recently regarding it. That is, it’s a teachable moment for those who are interested in learning.
The basic problem is that the video’s “challenge” woefully misunderstands ID and the logic by which we infer design. It claims that ID only claims that a gene is “unambiguously designed” when we find that:
(1) No homology for other genes exist.
(2) No alternative or prior function exists.
Each criterion makes an extremely poor test of ID, for designed structures often appear in similar forms in different designs, and designed structures can also have multiple functions. Let’s examine these two contrived criteria in turn.
Why Must Designed Structures Be Unique?
Regarding the first criterion, the homology criterion, the video claims that homology is found with at least 20% sequence identity over at least 100 amino acids, which would have an odds of less than 1/ 1028 of happening by chance. There’s actually much debate about what constitutes homology and what a non-arbitrary measure of homology should look like. For example, Teichmann and Veitia (2004) suggest that homology should not be inferred when there is less than a 60% sequence identity.2 If this is to be the measuring line, many claims of protein homology (including the claims in this video) would be in jeopardy. But for the sake of argument, we’ll take the video’s definition of homology.
The video’s argument effectively says that a gene must lack any known homologies and thereby be completely unique–basically an ORFan gene–in order for us to claim that it was designed. But why must this be so?
The video’s first criterion for detecting design seems eminently contrived and unreasonable as a test. As I explained in my recent Primer on the Tree of Life, designers commonly re-use similar components in different designs because they are effective at performing a common function:
why not consider the possibility that biological similarity is instead the result of common design? After all, designers regularly re-use parts, programs, or components that work in different designs (such as using wheels on both cars and airplanes, or keyboards on both computers and cell-phones)3
In this regard, we might actually expect to find similar proteins and genetic components among living organisms if life were designed.
If there is no known homology for a given gene, then that would dictate that the gene is effectively an ORFan gene. The existence of ORFan genes poses a problem for evolution (from whence would such an ORFan come?), but their non-existence would not pose a problem or ID. After all, many ID critics are quick to remind that evidence against evolution does not necessarily therefore constitute evidence for ID. (ID requires a positive case for design.) Thus, these ID-critics are testing ID inappropriately by trying to affirm ID simply by challenging evolution. But when it comes to predictions about biological similarity, both common design and common descent predict that it might exist. Thus, the presence of shared functionally similar sequences between different organisms does not make a good test of discriminating between design and descent.
Even leading evolutionists like Francis Collins recognize this point. Collins writes in The Language of God that genetic similarity “alone does not, of course, prove a common ancestor” because a designer could have “used successful design principles over and over again.”4 Collins is right. To again show how the video’s argument fails by analogy, if one discovers two similar Buicks in a junkyard, one would not conclude one car descended from the other. Rather, one would conclude that intelligent engineers modified plans from the first Buick to make the second. In the same way, the genetic similarity of two different proteins–in itself–is compatible with either common descent or common design. So rather than failing to make a case “unambiguously” for intelligent design, homology fails to make a case “unambiguously” for common descent.
Ignoring the possibility of common design, the video assumes that shared functional similarity necessarily indicates common ancestry. This video is simply applying what I called in my recent Primer on the Tree of Life the “main assumption” of neo-Darwinian tree-building:
[T]he first assumption that goes into tree-building is the basic assumption that similarity between different organisms is the result of inheritance from a common ancestor. That is, except for when it isn’t. (And then the similarity is purportedly said to be the result of convergent evolution, etc.) But even if we take this claim at face value — that similarity between different organisms is the result of inheritance from a common ancestor — let’s recognize it for what it is: a mere assumption. But are there other possibilities?
As for those other possibilities, Michael Behe explains in both The Edge of Evolution and Darwin’s Black Box that mere similarity is not enough to infer that a feature was produced by the neo-Darwinian mechanism of natural selection acting on random mutations:
Darwin’s Black Box: “Although useful for determining lines of descent … comparing sequences cannot show how a complex biochemical system achieved its function–the question that most concerns us in this book. By way of analogy, the instruction manuals for two different models of computer put out by the same company might have many identical words, sentences, and even paragraphs, suggesting a common ancestry (perhaps the same author wrote both manuals), but comparing the sequences of letters in the instruction manuals will never tell us if a computer can be produced step-by-step starting from a typewriter….Like the sequence analysts, I believe the evidence strongly supports common descent. But the root question remains unanswered: What has caused complex systems to form?”5
The Edge of Evolution: “[M]odern Darwinists point to evidence of common descent and erroneously assume it to be evidence of the power of random mutation.”6
These critics are thus mistaking sequence similarity as evidence for the neo-Darwinian mechanism of natural selection acting on random mutations. I would go further than Behe and argue that when we consider the possibility of common design, functional similarity (i.e. sequence homology) does not even provide “unambiguous” (a word used in the video as the necessary standard of proof for ID) evidence for common descent over common design. After all, to reiterate what Francis Collins admits, genetic similarity “alone does not, of course, prove a common ancestor” because a designer could have “used successful design principles over and over again.”7
Criterion 2: Repeating Ken Miller’s Errors
When you only read the arguments of critics, sometimes you begin to think that they have the monopoly on a subject. This must be the case of the YouTube video’s creators, who mimic Ken Miller’s straw man tests for irreducible complexity by stating: “We don’t want some protein that is used lots of ways or it can’t be part of an irreducibly complex system.”
Huh? These guys must be learning about ID from Ken Miller, and not from ID’s proponents. Miller has made similar arguments like this many times, and I wrote a lengthy response to Miller on this point in 2006 at Do Car Engines Run on Lugnuts? A Response to Ken Miller & Judge Jones’s Straw Tests of Irreducible Complexity for the Bacterial Flagellum that explains Miller’s error.
To repeat Miller’s assertion, he testified during the Dover trial that irreducible complexity (IC) is refuted if one sub-system can perform some other function in the cell:
Dr. Behe’s prediction is that the parts of any irreducibly complex system should have no useful function. Therefore, we ought to be able to take the bacterial flagellum, for example, break its parts down, and discover that none of the parts are good for anything except when we’re all assembled in a flagellum.8
The question becomes, “how is Behe’s argument for irreducible complexity different from that of Ken Miller, and this video?” Behe actually formulates irreducible complexity as a test of building an entire system. IC operates on a collection of parts, not each individual part. Even if a separate function could be found for a sub-system, the latter would not refute the irreducible complexity and the unevolvability of the system as a whole. To repeat Behe’s definition, Behe writes:
In The Origin of Species Darwin stated:
‘If it could be demonstrated that any complex organ existed which could not possibly have been formed by numerous, successive, slight modifications, my theory would absolutely break down.’
A system which meets Darwin’s criterion is one which exhibits irreducible complexity. By irreducible complexity I mean a single system composed of several well-matched, interacting parts that contribute to the basic function, wherein the removal of any one of the parts causes the system to effectively cease functioning.9
Thus, according to Darwin, evolution requires that a system (including its sub-parts), be functional along each small step of their evolution to the final system. If this were the case, then the complexity of a system would be easily reducible. Yet one could find a sub-part that could be useful outside of the final system, and yet the total system would still face many points along an “evolutionary pathway” where it could not remain functional along “numerous, successive, slight modifications” that would be necessary for its gradual evolution. In other words, sub-parts could perform other functions outside of the system, but the system itself could be irreducibly complex.
Thus, Miller and the video mischaracterize Behe’s argument as one which focuses on the non-functionality of subparts, when in fact Behe’s argument actually focuses on the ability of the entire system to assemble, even if sub-parts can have functions outside of the final system.
Two analogies will help explain the fallacy in the video.
To understand how Miller and the video’s test fails to accurately apply to Behe’s formulation of irreducible complexity, consider the example of a car engine and a bolt. Car engines use various kinds of bolts, and a bolt could be seen as a small “sub-part” or “sub-system” of a car engine. Under Miller’s logic, if a vital bolt in my car’s engine might also to perform some other function–perhaps as a lugnut–then it follows that my car’s whole engine system is not irreducibly complex. Such an argument is obviously fallacious.
In assessing whether an engine is irreducibly complex, one must focus on the function of the engine itself, not on the possible function of some sub-part that may operate elsewhere. Of course a bolt out of my engine could serve some other purpose in my car. However this observation does not explain how many complex parts such as pistons, cylinders, the camshaft, valves, the crankshaft, sparkplugs, the distributor cap, and wiring came together in the appropriate configuration to make a functional car engine. Even if all of these parts could perform some other function in the car (which is doubtful), how were these parts assembled properly to construct a functional engine? The answer requires intelligent design.
Behe asserts that a system is irreducibly complex if the system stops functioning upon the removal of one part. This is the appropriate test of Darwin’s theory because it asks the question, “Is there a minimal level of complexity which is required for functionality of this system?” Clearly my car’s engine has a core set of parts necessary in order for it to function. The ability of an engine bolt to also serve as a lugnut does not refute the irreducibly complex arrangement of parts necessary to make the final engine-system functional.
Behe never suggests that subsystems or sub-parts cannot play some other role in the cell–in fact he suggests the opposite. Rather, Behe simply argues that evolution requires that the total system must be built up in a slight, step-by-step fashion, where each step is functional. When a certain core number of parts must be arranged in a particular pattern for a system to function, we have irreducible complexity. Period.
Likewise, my laptop’s power cord might be able to also be used power my toaster. But does that mean that my laptop does not have a core number of parts that are required for it to function? You answer the question for yourself.
The video’s second criterion for detecting design is therefore also utterly fallacious.
Answering the Challenge, Challenging the Critics to Understand Intelligent Design
The video then claims that “you [Discovery Institute] have not pointed to a single gene that shows evidence of a non-evolutionary design,” saying that we haven’t “discovere[d].” To restate the obvious, apparently these critics simply aren’t familiar with Discovery Institute or ID literature.
In Darwin’s Black Box, Michael Behe has described systems with dozens of genes which, as they form irreducibly complex systems, show evidence of not having been produced by natural selection acting on random mutations, and instead show evidence of design.
Doug Axe’s research likewise studies genes that it turns out show great evidence of design. Axe studied the sensitivities of protein function to mutations. In these “mutational sensitivity” tests, Dr. Axe mutated certain amino acids in various proteins, or studied the differences between similar proteins, to see how mutations or changes affected their ability to function properly.10 He found that protein function was highly sensitive to mutation, and that proteins are not very tolerant to changes in their amino acid sequences. In other words, when you mutate, tweak, or change these proteins slightly, they stopped working. In one of his papers, he thus concludes that “functional folds require highly extraordinary sequences,” and that functional protein folds “may be as low as 1 in 10^77.”11 The extreme unlikelihood of finding functional proteins has important implications for intelligent design.
Since Darwinian evolution only preserves biological structures which confer a functional advantage, this indicates it would be very difficult for such a blind mechanism to produce functional protein folds. This research also shows that there are high levels of specified complexity in enzymes, a hallmark indicator of intelligent design: Only forward thinking intelligent agents could find the extremely unlikely amino acid sequences that yield functional proteins. Axe himself has confirmed that this study adds to the evidence for intelligent design, writing: “In the 2004 paper I reported experimental data used to put a number on the rarity of sequences expected to form working enzymes. The reported figure is less than one in a trillion trillion trillion trillion trillion trillion. Again, yes, this finding does seem to call into question the adequacy of chance, and that certainly adds to the case for intelligent design.”12
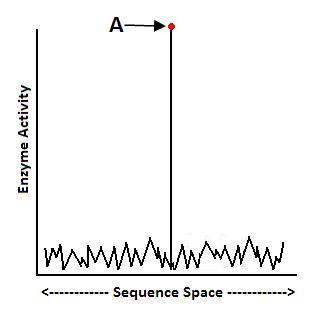 Biologist Doug Axe’s research suggests that the “fitness landscape” for many enzymes might look something like this, where the y-axis can be seen as representing enzyme activity, and the x-axis represents possible amino acid sequences. If Axe’s empirical studies are correct, then enzymes likely sit at the peak of their fitness landscapes (Point A), and there are extremely high levels of complex and specified information in proteins–informational sequences that would be unlikely to be found via blind trial-and-error Darwinian processes, and which point to intelligent design. Biologist Doug Axe’s research suggests that the “fitness landscape” for many enzymes might look something like this, where the y-axis can be seen as representing enzyme activity, and the x-axis represents possible amino acid sequences. If Axe’s empirical studies are correct, then enzymes likely sit at the peak of their fitness landscapes (Point A), and there are extremely high levels of complex and specified information in proteins–informational sequences that would be unlikely to be found via blind trial-and-error Darwinian processes, and which point to intelligent design.
The video taunts Discovery Institute to name a specific gene that shows evidence of design. At the risk of dignifying this highly misinformed video, some of the enzymes empirically studied in Dr. Axe’s work were those containing β-lactamase domains in E. coli, such as TEM-1 penicillinase. |
So Discovery Institute and ID proponents most certainly have described genes that show evidence of a non-Darwinian and intelligent design. We’ve simply done it through a viable mode of detecting design: finding biological systems that contain high levels of specified (including irreducible) complexity.
This is the proper way to detect design and to test for design, not inventing contrived criteria that claim that systems must be totally unique and perform only one function before they can be designed. Given that designers regularly re-use parts that work in different designs, and may even use a part to perform multiple functions, we can easily dispense with the video’s uninformed modes of detecting design.

The Signature in the Cell
The video opens by showing Stephen Meyer arguing that “when we find information in the DNA in this four-character digital code, it’s a logical inference and explanation to say that an intelligent agent of some kind played a role in the origin of those living systems.” The video then challenges Meyer and Discovery Institute to provide evidence backing this statement statement, which is amusing since there will be no better elaboration on the scientific case for intelligent design based upon the information in DNA than Dr. Meyer’s forthcoming book Signature in the Cell: DNA and the Evidence For Intelligent Design, which comes out next month.
The right question is, where does your information come from? Stephen C. Meyer has elegantly explained that we know only one source of high levels of complex and specified information:
[W]e have repeated experience of rational and conscious agents-in particular ourselves-generating or causing increases in complex specified information, both in the form of sequence-specific lines of code and in the form of hierarchically arranged systems of parts. … Our experience-based knowledge of information-flow confirms that systems with large amounts of specified complexity (especially codes and languages) invariably originate from an intelligent source from a mind or personal agent.13
Meyer’s forthcoming book, for those critics who are willing read it, will more than answer the video’s challenge.
References Cited:
[1.] Spending a short 2 minutes on Discovery Institute’s website quickly uncovers that Stephen Meyer is a Senior Fellow, and Director of the Center for Science and Culture, whereas the President of Discovery Institute is Bruce Chapman.
[2.] Sarah Amalia Teichmann and Reiner Albert Veitia, “Genes Encoding Subunits of Stable Complexes Are Clustered on the Yeast Chromosomes: An Interpretation From a Dosage Balance Perspective,” Genetics, Vol. 167:2121–2125 (August, 2004).
[3.] Casey Luskin, “A Primer on the Tree of Life”
[4.] Francis Collins, The Language of God, page 134.
[5.] Michael Behe, Darwin’s Black Box, pgs. 175-176 (Free Press, 1996).
[6.] Michael Behe, The Edge of Evolution, pg. 95 (Free Press, 2007).
[7.] Francis Collins, The Language of God, page 134.
[8.] Kenneth Miller Kitzmiller Testimony, Day 1, PM Session, page 16.
[9.] Michael Behe, Darwin’s Black Box, pg. 39 (Free Press, 1996).
[10.] Douglas D. Axe, “Estimating the Prevalence of Protein Sequences Adopting Functional Enzyme Folds,” Journal of Molecular Biology, 1-21 (2004); Douglas D. Axe, “Extreme Functional Sensitivity to Conservative Amino Acid Changes on Enzyme Exteriors,” Journal of Molecular Biology, Vol. 301:585-595 (2000).
[11.] Douglas D. Axe, “Estimating the Prevalence of Protein Sequences Adopting Functional Enzyme Folds,” Journal of Molecular Biology, 1-21 (2004).
[12.] “Scientist Says His Peer-Reviewed Research in the Journal of Molecular Biology “Adds to the Case for Intelligent Design”
[13.] Stephen C. Meyer, “The origin of biological information and the higher taxonomic categories,” Proceedings of the Biological Society of Washington, Vol. 117(2):213-239 (2004).